Competencies and Academic Standards Exchange Best Practice and Implementation Guide
IP Disclosures
The following participating organizations have made explicit license commitments to this specification:
| Organization Name | Date election made | Necessary claims | Type |
|---|---|---|---|
| UNICON INC. | 2025-01-14 | No | RF RAND (Required & Optional Elements) |
| Common Good Learning Tools | 2025-01-15 | No | RF RAND (Required & Optional Elements) |
| Infinite Campus | 2025-01-23 | No | RF RAND (Required & Optional Elements) |
List of Contributors
The following individuals contributed to the development of this document:
Revision History
| Version | Doc Version | Date | Comments |
|---|---|---|---|
| CASE 1.1 Final Release | 2024-11-01 | The first formal Final Release that is ready for public adoption and implementation. This version includes an update of what's new in CASE 1.1, including best practices from early adopter implementers, associations to non-case frameworks and translations, removal of support for JSON-LD, use cases for HEd, and extensions. |
Abstract
The 1EdTech Competencies and Academic Standards Exchange® (CASE®) standard facilitates the exchange of information about learning outcomes, competencies and skills. CASE can also transmit information about rubrics and criteria for performance of tasks. CASE supports association across frameworks so frameworks and items can be related and aligned. By implementing CASE, it is possible to electronically exchange outcomes, skills and competency definitions so applications, tools and algorithms can readily access and act upon this data. Having universal identifiers for learning outcomes, skills and competencies makes it possible for any tool or application to share precise information between systems easily, internally or across the web. This includes learning management systems, assessment tools, curriculum management, credentialing and hiring platforms.
This is accomplished via a data model as represented in JSON, and exchanged via a REST API. This document explains the covered use-cases, the data involved, and the mechanisms for exchanging them.
Scope
The Competencies and Academic Standards Exchange (CASE)'s Work Group mission is to create a globally adopted technical specification and support shared tools within 1EdTech community, that enables trusted agents to manage and publish Academic Standards and Competency Framework Documents.
Document Set
Normative Documents
Informative Documents
Conformance Statements
As well as sections marked as non-normative, all authoring guidelines, diagrams, examples, and notes in this specification are non-normative. Everything else in this specification is normative.
The key words MAY, MUST, MUST NOT, OPTIONAL, RECOMMENDED, REQUIRED, SHALL, SHALL NOT, SHOULD, and SHOULD NOT in this document $are to be interpreted as described in $[object Object].
An implementation of this specification that fails to implement a MUST/REQUIRED/SHALL requirement or fails to abide by a MUST NOT/SHALL NOT prohibition is considered nonconformant. SHOULD/SHOULD NOT/RECOMMENDED statements constitute a best practice. Ignoring a best practice does not violate conformance but a decision to disregard such guidance should be carefully considered. MAY/OPTIONAL statements indicate that implementers are entirely free to choose whether or not to implement the option.
The Conformance and Certification Guide for this specification may introduce greater normative constraints than those defined here for specific service or implementation categories.
The CASE Ecosystem for Learning Standards, Skills, and other Competencies
Broadly speaking, the goal of education is to help people acquire and retain information and learn skills. In modern educational systems, students taking a given course of study are generally expected, by the end of the course, to meet a set of competencies, which may be classified as learning standards, objectives, expectations, etc., specified by the agency overseeing the educational system, which formally define the information and skills to be learned. These competency frameworks have traditionally been published, in the internet age, in PDF documents distributed via the agency’s website.
The problem with this publishing method is that while PDFs are readable by humans, they are not parseable by machines. Both formative and summative educational resources, which are increasingly distributed and consumed digitally, are also increasingly required to be aligned to the competencies they are designed to support and assess. In addition, tools reporting on students’ progress and achievements in educational activities also increasingly need to refer to these competencies. For a digital system to align and refer to competencies, they need a machine-readable representation of those competencies. And for these systems to interface with each other, these representations need to use a standardized format and have canonical, unique, dereferenceable identifiers, so that all systems are “speaking the same language” when referring to competencies.
1EdTech’s goal in publishing this CASE specification has been to support the creation of a CASE ecosystem, where standards issuing agencies and institutions (e.g. Georgia Department of Education, Gwinnett Public Schools, Colleges and Universities, WIDA, The College Board, and AACN) encode their competency frameworks using the standardized CASE JSON format, then publish this JSON data on a 1EdTech-certified CASE publishing webserver, making the data available via a set of standardized CASE REST APIs to anyone who wants to retrieve it.
Systems that provide educational services (e.g. learning management, learning object repository, student information, assessment, and comprehensive learner record systems), publishers of educational resources, and other educational agencies can then retrieve the CASE JSON representing any competency framework of interest from the issuing agency’s CASE server using these standardized APIs. Resources (instructional videos, test items, report cards, badges, etc.) can then be aligned to the canonical CASE identifiers representing competencies, thereby facilitating successful interactions between systems.
Here are examples of some of the educational benefits that can accrue for an issuing agency (e.g., in the example below, a state), and the educators and learners the agency supports, when the agency publishes their competencies in CASE format:
The state can provide a tool that uses the CASE-formatted data to implement an interactive interface for educators, students, and family members to browse and search competencies, as well as visualize associations between competencies (see, e.g., South Carolina DOE’s Satchel site).
Textbook publishers can use the CASE APIs to pull frameworks from the state’s CASE publishing tool, then align ebook and related resources to CASE identifiers, and publish these resources using Common Cartridges that include these alignments.
A learning object repository can also pull frameworks from the state’s CASE publishing tool, so that when it ingests these Common Cartridges, it can allow teachers browsing the LOR to view the competency alignments and search by competency.
An educator can import a resource from the LOR into a learning management system, with the CASE identifier alignments coming along for the ride; the LMS can also pull frameworks from the state’s CASE publishing tool, thereby allowing the educator to view the alignments there as well.
An assessment system can pull the CASE frameworks from the state to align test items to the state competencies, so that test result reports can be broken down by competency. At institutions of higher education, learning outcomes can be pulled into an LMS or assessment solution from their curriculum management system so that they can close the loop on both curricular and student performance.
Any public or private organization that wishes to take on the challenge can create a system to align resources to the state-provided CASE identifiers; the state’s officially-published competency statements can be used, at no cost, with machine learning models and other algorithms to make alignment suggestions.
An external reporting tool can pull the CASE frameworks, then pull usage data from the LMS and test results from the assessment system, with the CASE identifier alignments again coming along for the ride in both cases; this tool can then generate a report that, e.g., analyzes how effective the learning resources were in helping students achieve high test scores against the corresponding competencies.
Badges and comprehensive learner records can compactly refer, via the CASE identifiers and URIs, to the competencies covered in a course of study, so that someone evaluating the merit of the badge or CLR can be directed back to the state’s canonical source of truth for the competencies and therefore understand exactly what the student learned.
If the state needs to update the definitional data associated with any competency, they can do so at any time, and all the systems noted above can pull this updated data, updating their cached version of the data via the canonical CASE identifiers.
An institution's curriculum system could share its Curriculum Maps and Pathway definitions with its Assessment and Credentialing systems using CASE to represent both courses and learning outcomes/competencies.
The CASE Data Model
The CASE data model includes definitions for a number of JSON structures, detailed at 1EdTech Competencies and Academic Standards Exchange (CASE) Service Information Model 1.1. Please see this document for additional, in-depth definition of CASE terms and field descriptions.
The relationships between the most significant entity types in current use are described at a high level here, followed by a representative use case, then descriptions of and best practices for the currently-most-widely-used properties of each entity.
CASE JSON Entity Types
A CASE Competency Framework Package (CFPackage) is a container object for the data (encoded using the entity types described below) that represents a competency framework. The words “framework” and “package” are sometimes used interchangeably; technically, the package is the data structure that represents the conceptual framework.
A CFDocument is the “head” entity for a framework; each CFPackage must include one and only one
CFDocumentJSON object. It defines what the framework represents, and the identifier of the CFDocument is used as the identifier of the CFPackage.A CFItem represents a competency. A CFPackage must include a
CFItemsarray, which can include any number [0..n] of CFItem objects.A CFAssociation represents an “association” — some type of relationship — between a CFItem and some other entity. A CFPackage must include a
CFAssociationsarray, which can include any number [0..n] of CFAssociation objects.A CFPackage may also include a
CFDefinitionsobject, which may include the following properties; see [] for definitions of these structures:CFConcepts: array of [0..n]CFConceptobjectsCFSubjects: array of [0..n]CFSubjectobjectsCFLicenses: array of [0..n]CFLicenseobjectsCFItemTypes: array of [0..n]CFItemTypeobjectsCFAssociationGroupings: array of [0..n]CFAssociationGroupingobjectsFinally, a CFPackage may include a
CFRubricsarray of [0..n]CFRubricobjects. Each CFRubric includes aCFRubricCriteriaarray of [0..n]CFRubricCriterionobjects, and each CFRubricCriterion includea aCFRubricCriterionLevelsarray of [0..n]CFRubricCriterionLevelobjects. CASE rubrics are not yet widely used, so best practices are not specified here; see 1EdTech Competencies and Academic Standards Exchange (CASE) Service Information Model 1.1 for technical specs about rubrics.Representative Use Cases
For US K-12 standards issuing agencies (e.g. state departments of education), a representative use case is Georgia’s K-12 Standards for English Language Arts (SY2025-2026). The CFPackage for this framework includes:
The
CFDocument, with the identifier (391c3abe-c1ec-4a4a-a942-c9e152b35102) that canonically and uniquely represents the entire framework, its title and a description, and metadata such as subject area, education levels, language, adoption status, etc.An array of approximately 2,300
CFItems. Many CFItems includes aCFItemTypeproperty that specifies its type; this framework includes items with types Big Idea, Course, Domain, Expectation, Grade Band, Skill, and Standard. The CASE spec places no limit on the vocabulary of item types that any framework can employ.An array of approximately 4,100
CFAssociations. The CASE spec does define a fixed vocabulary of association types; the types used in this framework include:isChildOf(~2,300): These associations define a hierarchical tree structure for the CFItems. EachisChildOfassociation’s origin is the identifier of the child CFItem; its destination is the identifier of the “branch” CFItem of the tree from which the child hangs. Figure Xa shows how a subset of theseisChildOfassociations are visually represented in Georgia’s SuitCASE tool.precedes(~1,770): This framework includes competencies for grade levels K-12, and is designed such that most competencies follow “progressions” through some or all of the grade levels. These progressions are represented in the CASE framework by including associations specifying, e.g., that standard 3.L.V.2.a precedes standard 4.L.V.2.a, that 4.L.V.2.a precedes standard 5.L.V.2.a, and so on. The figure below shows how a subset of theseprecedesassociations are visually represented in Georgia’s SuitCASE CASE publishing tool.An abridged version of the CFPackage JSON for this framework (with the CFDocument, 2 CFItems, and 3 CFAssociations) appears below; the full framework JSON is available from the framework’s CASE API URL:
/ims/case/v1p1/CFPackages/391c3abe-c1ec-4a4a-a942-c9e152b35102.Three Models of Curriculum Maps in CASE
CASE was designed to handle much more complex use cases, such as sets of alignments used most commonly in higher education as Curriculum Maps. This is where CFAssociation and CFAssociationType and their Extension property come into play. In addition to creating alignments between curricular objects (Course, Outcome, Standard, etc), CASE supports the ability to specify the rubric used to assess a competency or learning outcome as part of a package.
Course to Learning Outcomes and Competencies
[Graphical Representation & Explanation]
Here is the CASE structure for the Curriculum Map:
Course Learning Outcome to Program and Institutional Outcomes
[Graphical Representation & Explanation]
Here is the CASE structure for the Curriculum Map:
Curriculum Map with Rubrics Intended for Learning Outcomes Covered
[Shows Rubric aligned to Program Learning Outcomes (PLO) diagram]
Here’s the CASE for the Rubric:
These can be added to any curriculum map package. Now, combined with CLR, you can have a truly “closed loop” between curriculum design, assessment, and a student’s learner records.
Best Practices for Key Properties of CASE Entities: Properties Common to All Entity Types
All CASE entity types, including CFDocuments, CFItems, and CFAssociations, include the following four properties:
identifier
identifier(required): a [formal description, noting that it should be a GUID of a particular type]. For example, the identifier for the CFDocument of the Georgia ELA framework described above is:391c3abe-c1ec-4a4a-a942-c9e152b35102Current best practice is to never change an entity’s identifier once it is established in an implemented CASE framework, even if one or more properties of the entity are later updated. The main point of establishing CASE-coded frameworks is to create alignments and associations to/with competencies; those alignments and associations are coded using competency identifiers, so changing competency identifiers would break these alignments and associations. See here for detailed best practices around change management for CASE data.
uri
uri(required): a [Uniform Resource Identifier].Current best practice is to set the
urifield of a CFItem/CFDocument/CFAssociation/etc to the CASE REST API url for retrieving that entity, using the latest CASE version that was supported by CASE the publishing system at the time the entity was last saved. For example, theurifield for the CFDocument of the Georgia ELA framework described above is:https://case.georgiastandards.org/ims/case/v1p0/CFDocuments/391c3abe-c1ec-4a4a-a942-c9e152b35102This explicitly defines the
urifield as a means of checking the source of truth for the entity to see if a cached copy of the entity needs to be updated.This has the side benefit of effectively specifying which CASE version was in place when the entity was last edited, and therefore which versions the entity should be expected to explicitly support (e.g. if it has a /v1p1
uri, you should be able to get a 1.1 or 1.0 version of the entity, but a call to the /v1p2 REST API should not be expected to return fields added in CASE 1.2).So if the entity was initially authored using CASE 1.0 and remains unchanged, its
uriwould be a /v1p0 url (even if another system uses the /v1p1 version of the API to request the entity). However, if the entity is changed after the publishing system was updated to support CASE 1.1, theuriwould also be changed at that point.lastChangeDateTime
lastChangeDateTime(required): [formal description]. For example, the lastChangeDateTime for the CFDocument of the Georgia ELA framework described above is:2024-06-13T18:46:03+00:00Best practice is to always update the lastChangeDateTime of any CASE entity whenever any property of the entity is changed in any way. In addition, best practice is to change the lastChangeDateTime of the CFDocument of a CFPackage any time any entity within the package is updated. These lastChangeDateTime updates can thereby serve as “hooks” allowing consuming systems to easily determine when something in a framework has changed, and exactly what in the framework has changed.
extensions
extensions: while the CASE 1.0 spec explicitly disallowed “proprietary data elements” in CASE JSON, CASE 1.1 explicitly allows CFItems, CFDocuments, and CFAssociations, and other entities to be “extended” to include field names and values that are outside the spec.extensionsfield, and/or any extension sub-fields, that the system doesn’t “know” or “care” about.extensionsfield, we avoid namespace collisions with field names that may be introduced in future CASE versions.sourceItemIdentifierbest practice below)Do Not use NULL Values
Best practice is to not use values of NULL for any CASE fields (this is a general best practice for most 1EdTech standards). For string fields, empty strings are sometimes acceptable values (see specs), but for fields that are optional, if no value is to be specified, best practice is to simply do not include that field.
Best Practices for Key Properties of
CFDocumentEntitiesKey properties of the CFDocument entity structure are given below (this is not a complete list of all properties; see [XXX])
identifier(required): see aboveuri(required): see abovelastChangeDateTime(required): see aboveextensions(optional): see abovetitle(required): the title of the framework (e.g.Georgia’s K-12 Standards for English Language Arts (SY2025-2026))creator(required): the creator of the competency framework. For example, the creator for Georgia’s state ELA standards is the Georgia Department of Education.publisher(optional): the entity responsible for publishing this competency framework in CASE format. Note that the creator and publisher could be the same entity; or one entity may be publishing a CASE encoding of a framework originally created by another entity. For example, CASE Network currently includes many frameworks for whom thecreatoris a state department of education, but thepublisheris Common Good Learning Tools, who has coded the state’s frameworks in CASE format.adoptionStatus(optional but recommended): the publication status for the document (e.g.Implemented). Though not required, best practice is to always include a value for this property. See here for current best practices for adoptionStatus values.language(optional): the “base language” for the framework (e.g.enfor English oresfor Spanish).officialSourceURL(optional): a link (url) to a website or document (often a PDF) where the framework and/or the competencies in the framework are described (e.g.https://www.gadoe.org/Curriculum-Instruction-and-Assessment/Curriculum-and-Instruction/Pages/English-Language-Arts-Program.aspx). For frameworks that were not originally authored in a CASE publishing system, this is often a link to the PDF that was used as the source for the CASE “translation” of the framework.subject/subjectURI(optional): One or more academic areas covered by the framework (e.g.['English']). Note that both of these properties should be represented as arrays (despite the singular property names), and that the subject(s) may be specified in thesubjectarray or thesubjectURIarray or both; best practice is that if both are included, they should not specify different lists of subjects :).description(optional): a human-readable description of the framework/document. May include markdown or LaTeX.notes(optional): a space for additional comments about the framework/document. May include markdown or LaTeX.version(optional): there is no established best practice around what values to use for this property. Some organizations simply enter the year the framework was first implemented; some organizations use a detailed scheme to track updates to the framework; many organizations simply leave the field blank.licenseURI(optional): if included, this should a reference to aCFLicenseobject in theCFLicencesarray ofCFDefinitions, which gives a legal description (or link to such a description) of what consumers of the framework are allowed to do with the data in the framework. Many organizations choose to leave this blank.statusStartDateandstatusEndDate(optional): as described here, thestatusStartDateandstatusEndDatefields can be used to specify the date a competency framework becomes “officially implemented” by the issuing agency, and the date the framework ceases to be officially implemented.frameworkType(optional): new in the CASE 1.1 spec; the vocabulary for frameworkType values is open, but see here for current best practices.caseVersion(required in CASE 1.1 and later): new in the CASE 1.1 spec. The caseVersion property must be included in the CFDocument and have the value1.1for frameworks published using the CASE 1.1 spec. Since the CASE 1.0 spec did not include this property, and the 1.0 spec does not allow for non-defined properties,caseVersionmust not be specified in CASE 1.0 frameworks.Best Practices for Key Properties of
CFItemEntitiesKey properties of the CFItem entity structure are given below (this is not a complete list of all properties; see [XXX])
identifier(required): see aboveuri(required): see abovelastChangeDateTime(required): see aboveextensions(optional): see abovefullStatement(required): thefullStatementis the official statement of the competency, as defined by the issuing agency (creator). May include markdown or LaTeX.humanCodingScheme(optional): a “code” for the item that is easily referrable by humans, e.g. RL.5.1. Best practice is that no two CFItems in the same framework should have the same humanCodingScheme value unless the two items are exact copies of each other (see here. Also note that this field is optional, so CASE consumers should not assume that ever CFItem will have a humanCodingScheme value.notes(optional): a space for additional comments about the item. For example, many frameworks include “clarifying statements” in the notes field. May include markdown or LaTeX.CFItemType/CFItemTypeURI(optional): specifies what type of competency the CFItem represents. There is no fixed vocabulary for item types in CASE; each framework defines a classification scheme for the CFItems in the framework via the set of CFItemTypes it utilizes. Note that each CFItem may include either aCFItemTypeor aCFItemTypeURI, may include both fields, or may include neither field (in which case the item type is undefined). See here for more information.educationLevel(optional):language(optional): the language in which this CFItem’s statement is expressed. Note that if an individual CFItem does not include a language field, the item should be considered to “inherit” the language field specified in the framework’s document (if the document includes a language field).statusStartDateandstatusEndDate(optional): As described here, thestatusStartDateandstatusEndDatefields can be used to specify the date a competency framework becomes “officially implemented” by the issuing agency, and the date the framework ceases to be officially implemented.Best Practices for Key Properties of
CFAssociationEntitiesKey properties of the CFAssociation entity structure are given below (this is not a complete list of all properties; see [XXX])
identifier(required): see aboveuri(required): see abovelastChangeDateTime(required): see aboveextensions(optional): see aboveassociationType(required):isChildOfassociations define the “tree structure” of a competency framework. Other association types are used to specify relationships between items, or (new in CASE 1.1) relationships between a CFItem and some other entity. See here for more information.originNodeURI(required) anddestinationNodeURI(required): these two properties specify the two entities involved in the associations. Each is itself an object, withidentifier,uri, andtitlefields. For most associationTypes, both should refer to a CFItem, so theidentifierandurifor each node should be theidentifieranduriof the referee CFItem (while theidentifierandurivalues that are direct children of the CFAssociation object refer to the CFAssociation itself). If the best practice forurivalues is followed, the full CFItem for each node can be retrieved by making a REST API call to the node’suri; best practice is for thetitleto be a human-readable indicator of the item for use when the full CFItem is not retrieved. Note that the origin CFItem, the destination CFItem, or both could “reside” in the same framework where the CFAssociation is specified, or in a different framework.sequenceNumber(optional; recommended forisChildOfassociations): this property is only relevant forisChildOfassociations, where it specifies the sequence of child items of a given parent item.notes(optional; new in CASE 1.1): a space for additional comments about the association. May include markdown or LaTeX.Other CASE Best Practices
This section of the implementation guide describes best practices for organizations publishing CASE frameworks and organizations consuming CASE data.
CASE Entity URI Values
The official CASE specs state that the
urivalues for CASE entities should be “An unambiguous reference to the [CFDocument/CFItem/CFAssociation/etc] using a network-resolvable URI.”. The CASE working group now further recommends as a best practice that:The
urifield of every CASE entity should be the CASE REST API url for retrieving that entity from the entity’s source-of-truth CASE publishing tool, using the latest CASE version that was supported by the publishing system at the time the entity was last saved.So if the entity was initially authored using CASE 1.0 and remains unchanged, its
urishould be a /v1p0 url (even if another system uses the /v1p1 version of the API to request the entity).However, if the entity is changed after the publishing system is updated to support CASE 1.1, the
urishould also be changed at that point.For example, the
urifield for South Carolina’s ELA standard ELA.8.OE.1.a ishttps://standards.ed.sc.gov/ims/case/v1p0/CFItems/c2cad6e9-8b6b-44cf-89d9-913b5c0f0281.This best practice explicitly defines the
urifield as a means of checking the source of truth for the entity to see if a cached copy of the entity needs to be updated. It also has the side benefit of effectively specifying which CASE version was in place when the entity was last edited, and therefore which versions the entity should be expected to explicitly support (e.g. if it has a /v1p1uri, you should be able to get a 1.1 or 1.0 version of the entity, but in a future world where a CASE 1.2 spec exists, a call to the /v1p2 REST API should not be expected to return fields added in CASE 1.2).CFDocument adoptionStatus Vocabulary
Although the CASE spec does not delineate a fixed vocabulary for the
CFDocument.adoptionStatusproperty, the CASE 1.0 best practices suggested that values be limited toDraft,Adopted, andDeprecated, and most frameworks published to date have one of these values.However, in the time since the initial adoption of CASE specs, agencies have found that the “Adopted” status is problematic, because often an agency officially approves a new set of standards a year or more prior to the date when the new standards are to be implemented by constituents of the agency. If the agency publishes a CASE representation of the new framework as soon as possible as soon as it is officially finalized, players in the ecosystem can have the benefit of preparing to align resources to the new framework identifiers; but the new framework is not, in this liminal period, “Draft”; it has in some ways already been “Adopted”, but there may be an older version of the framework that has status “Adopted” and is still in use.
Therefore, the working group has agreed to the following new vocabulary of adoptionStatus values as the new best practice:
Draft: the CASE framework, and the competencies being coded in the CASE framework, are still being actively authored, so the CASE framework should not yet be considered definitive.
Pending Implementation: authoring of the CASE framework is complete and has been officially approved by the issuing agency. However, constituents of the issuing agency are not yet being governed by this framework's competencies (they may still be governed by a previous set of competencies).
Implemented: authoring of the CASE framework is complete and been officially approved, and constituents of the issuing agency are currently being governed by this framework's competencies. This value replaces the previous “Adopted” value (that is, for frameworks published under the CASE 1.0 best practices, adoptionStatus “Adopted” should be considered equivalent to the new “Implemented” status).
Retired: the competencies represented by the CASE framework are no longer being implemented by constituents of the issuing agency. This value replaces the previous “Deprecated” value (that is, for frameworks published under the CASE 1.0 best practices, adoptionStatus “Deprecated” should be considered equivalent to the new “Retired” status). The reason for this change is that “deprecated” is a technical term that many educators are unfamiliar with.
Competency Change Management
One of the most important reasons that agencies adopt CASE to encode their competencies is to establish a permanent, “official” identifier/GUID to represent each competency, so that systems can interoperate around competencies by referring to these identifiers.
Therefore, once a framework of competencies has been “officially published”, the identifiers established to represent the competencies should not change.
After official publication, the content of the published competencies should, as much as possible, also remain stable. However, we must acknowledge and deal with the facts that:
The CASE spec, allows for various ways to deal with corrections, revisions, retirements, and replacements of competencies. What follows is a catalog of some of the types of changes to CASE content that can occur, with best practices for how these changes should be dealt with.
Complete Overhaul of a Framework
(e.g. GA Math):
New Item(s) Added in an Implemented Framework (e.g. new course)
Item(s) Removed from an Implemented Framework (e.g. a deprecated course)
DON’T delete the CFItem, set statusEndDate to date the item is deprecated optionally add text (e.g. “[DEPRECATED]”) to fullStatement (and optionally alter humanCodingScheme, e.g. by adding “X”), but do not otherwise edit the CFItem properties optionally move CFItem(s) to a different "folder" (e.g. titled “Deprecated Items”) in the framework this preserves the CFItems as a permanent record of the now-deprecated competencies.
Small Change to the Content of an Item in a Framework (e.g. “Creek” -> “Muscogee (Creek)”)
Change to an Item that Substantially – in the judgment of the issuing agency – changes the meaning of the item
Additional notes
To reiterate what has been noted above, a CFItem’s lastChangeDateTime should be updated when any change is made to the item.
In addition, any time anything in a framework is changed (e.g. a CFItem or CFAssociation is changed in any way or moved in the hierarchy, a new CFItem/CFAssociation is added, or an existing CFItem/CFAssociation is removed) update the lastChangeDateTime of the CFDocument for the framework. This is needed because many consumers check the lastChangeDateTime of the CFDocument (e.g. via the “getAllDocuments” API) to know whether or not they need to re-pull the framework data.
DON’T change or clear the statusStartDate for a CFItem after the specified statusStartDate has passed. This allows the statusStartDate to serve as a permanent record of when the item became “official”.
It is acceptable to move the statusStartDate forward if the date hasn’t been reached (e.g. if there is a delay in when the item becomes official)
Competency “Reswizzling”
When an issuing agency publishes the CASE representation of a competency, the published CASE GUID should be the universal identifier used to designate the “educational significance” of that competency.
This is a big part of why CASE is useful for any digital education ecosystem, because it means that if we align resources of all types (texts, videos, test items, rubrics, report cards, etc) to these source-of-truth CASE GUIDs, the CASE GUIDs constitute a “rosetta stone” that aligns all those resources to each other.
The CASE specification states that each CFItem GUID should be included in one and only one framework, and only in a single place in the tree structure of that framework.
However, there are many situations where:
Agencies wish to create new collections (frameworks) including competencies pulled from other, previously existing, frameworks. Examples:
District-specific versions of state frameworks: districts sometimes want to start with their state’s standards, but then layer on their own clarifications/sub-standards/etc.
Frameworks representing competencies for microcredentials, badges, course syllabi, etc.: for example, a course syllabus for an interdisciplinary class may include standards drawn from a state’s science, math, and social studies standards.
Agencies wish to include in a framework multiple “pathways” including the same competencies in different arrangements. Example:
The first situation involves between-framework copies of CFItems, while the second situation involves within-framework copies of CFItems. The previous CASE best practices implied that to “reswizzle” CFItems in any of these ways, new GUIDs would need to be created to identify the second (or third or fourth, etc.) copy of a CFItem. The CASE working group now recommends a different set of best practices for these two situations.
Within-Framework Reswizzling
When creating a duplicate copy of a CFItem within the same framework, a CASE publishing/authoring tool should create a new CFItem for which all fields from the original CFItem are duplicated, except that:
CFItem.identifiershould be set to a newly-minted GUID.CFItem.urishould be set to a new URI value including the new GUID.CFItem.lastChangeDateTimeshould be set to the date/time the copy is being created.CFItem.extensions.sourceItemIdentifiershould be set to theidentifier(GUID) of the original CFItem -- unless the original CFItem itself includes anextensions.sourceItemIdentifiervalue, in which case theextensions.sourceItemIdentifiervalue from the original should be copied to the duplicate.CFItem.extensions.sourceItemURIshould be set to the original CFItem’surivalue, or the original’sextensions.sourceItemURIif it existed.CFItem.extensions.sourceItemIdentifier/CFItem.extensions.sourceItemURImay optionally be set to duplicate the item’sidentifier/uri. This can serve as an indicator that this item is duplicated elsewhere in the framework.Referencing the best practices stated earlier for changes to CFItems, if changes are made to the duplicate CFItem that do not, in the agency’s judgment, change the meaning of the standard, the
sourceItemIdentifiervalue should remain pointing back to the original item.However, if the duplicate CFItem is later changed substantially (in the judgment of the issuing agency), the
sourceItemIdentifier/sourceItemURIvalues should be cleared from the duplicate item. Again, it is up to the agency to determine if/when a change merits breaking the link from the copy to the original. If the link is broken, the agency may choose to add anisRelatedToassociation (or some other associationType) to retain a more tenuous connection from the copy to the original.This best practice allows CFItems representing competencies that exist in multiple contexts within the framework to have a clear reference to the original source of truth of the competency (the sourceItemIdentifier) while also having a clear indicator of the unique context in which this version of the competency exists (the identifier). This in turn means that systems aligning resources to standards can use sourceItemIdentifier as a straightforward way to know when a resource aligned to one competency should probably be aligned to other identical competencies.
Example: California’s high school math standards are reswizzled in two alternative “pathways”, and are also included in the math framework organized by “conceptual category”, so many of the standards are instantiated in three different places in the framework. The “original” version of CFItem HSN-RN.A is coded as:
and one of the duplicates is coded as:
Between-Framework Reswizzling
Now consider use cases where we wish to create a duplicate copy of a CFItem in a different framework — that is, we wish to include a duplicate CFItem from framework A (e.g. a state’s Science learning standards framework) in a different framework B and not changed in any way (e.g. in a school district’s local Science learning standards framework). The previous best practice of making new CFItems, with new GUIDs, in “derivative” frameworks such as these leads to two problematic issues:
First, once there are multiple copies of a CFItem out there, how do we know which one should be considered the “source of truth” for the underlying competency?
Second, consider a world down the road where all 100+ school districts in Georgia have created “derivative frameworks” from the GA Math state standards. In this world there are 100+ different GUIDs representing standard MP3. For a resource provider looking to align resources for all 100+ districts, it would be challenging (to say the least) to maintain alignments to all 100+ GUIDs.
The new best practice for this use case is to not create a new CFItem at all. Instead, framework B should “alias” the original items from framework A (with their original GUIDs) via
isChildOfCFAssociations that reference those items from framework A in the associations’originNodeURIs and/ordestinationNodeURIs. This is diagrammed below.Best practice is that the CFItems from framework A that are aliased in framework B should be included in the CFPackage for framework B, so that another system requesting the entire package for framework B via the
getCFPackageAPI does not need to make separate requests for the aliased items. However, if thegetCFItemAPI is called for an aliased item, the returnedCFDocumentURIattribute should reference the item’s original framework (framework A).An additional best practice is to include, for each
isChildOfCFAssociationthat references an aliased item in itsoriginNodeURI, two extension properties:extensions.sourceDocumentIdentifierandextensions.sourceDocumentURI. These properties should point to the “source of truth” (i.e. framework A) for theoriginNodeURICFItem.Example: the original source-of-truth CFItem for Georgia’s science standard S8P1 is:
Columbia County (GA)’s derived science framework includes standard S8P1. In this framework’s
CFPackage, theCFItemfor S8P1 is identical to the CFItem above. TheCFAssociationfor S8P1 is:Note here that:
destinationNodeURI(which refers to the “parent” of the aliased S8P1 item), as well as theCFAssociationitself, have uri values pointing to the satchelcommons.com CASE server, which is where Columbia County’s framework is published.originNodeURIincludes the identifier and uri of the CFItem from the Georgia science framework, and thesourceDocumentIdentifier/sourceDocumentURIvalues point to the Georgia science framework itself; note that these two uris point to the case.georgiastandards.org server, which is Georgia’s CASE publishing tool.Framework Types
Not all CASE frameworks are for competencies or academic standards. For example, a district may wish to publish its Course Codes so that they can be referenced by other competencies. CASE 1.1 adds a new field
frameworkTypeto CFDocument to help framework creators indicate how the framework can be used. This does not restrict what items and types are allowed in that document, it is just an indicator of the primary purpose of the document.This is an open field to allow implementors to solve whatever problems they need, however the CASE Workgroup will define official framework types as the community defines interoperable types derived from frameworks in practice.
These definitions will consist of the value for the
frameworkTypeand a collection of CFItemTypes to be used when implementing a specific framework type. These definitions can grow over time without a release of CASE allowing for the community to evolve and create these as needed.It is not intended to certify proper usage of framework types for CASE 1.1.
Course Codes
The Course Code framework is intended to provide a shared implementation of Course Metadata in K12 that can be shared between states, districts, and educational product vendors. The intent is to describe a basic framework that can be extended by implementers as needed.
Use Cases
Item Types
The item types defined for this framework type are defined in the official CASE Types and Definitions framework. New types can be added over time, as of the generation of this implementation guide the item types are:
Implementation example
To indicate a Course Code CFDocument the
frameworkTypeshould beCourseCodes. This type and its items are defined in the CASE Types and Definitions official framework.This is an incomplete example the relevant fields for Course Codes.
Item Types
CASE does not specify a fixed vocabulary for CFItem types, allowing issuing agencies to freely define the set of item types that classify CFItems in any given framework.
CASE allows for two different ways that item types can be specified in CFItems: via a
CFItemTypestring property, and/or via aCFItemTypeURIobject property, which must reference a separateCFItemTypeobject in theCFItemTypesarray of theCFDefinitionsobject in a framework payload. TheCFItemTypestructure, if included, must provide adescriptionof the item type that consumers of the framework can use to interpret what items of the specified type represent.This should probably go without saying, but if publishers choose to provide both a
CFItemTypestring and aCFItemTypeURIobject in aCFItemstructure, best practice is that the CFItemType string should always exactly match thetitlefield of the correspondingCFItemTypeURIand theCFItemTypestructure from theCFDefinitionssection of the framework.Consumers should be aware, and handle, the fact that each CFItem can include either a
CFItemTypestring or aCFItemTypeURIobject or both — or neither.Association Types
CASE does specify a fixed vocabulary for CFAssociation types; specified values are
isRelatedTo,exactMatchOf,replacedBy,isChildOf,isPeerOf,precedes,isPartOf,exemplar,hasSkillLevel, andisTranslationOf.isRelatedTois considered by convention to be the “default” association type (i.e., if you’re not sure what association type to use, just use isRelatedTo).isTranslationOfwas added in CASE 1.1.The CASE 1.1 spec also adds support for the CFAssociationType vocabulary to be extended by using any string that starts with
ext:. For example, if a framework publisher wishes to differentiate between pairs of items that are “closely” vs “moderately“ related, they could choose to use CFAssociations with CFAssociationTypesext:closelyRelatedandext:moderatelyRelated. Best practice is that consumers of a framework that encounter extended association types should treat them asisRelatedToassociations if they lack additional information to interpret what the extended types mean.CFDocument, CFItem, and CFAssociation Extensions
Best practice is to
The CASE working group will keep here a running list of properties CASE publishers are implementing using
extensions. In future versions of the CASE spec, the working group may decide to “promote” some of these properties to the CFDocument entity model.CFItem Extensions
The CASE working group will keep here a running list of properties CASE publishers are implementing using
CFItem.extensions. In future versions of the CASE spec, the working group may decide to “promote” some of these properties to the CFItem entity model.Caching CASE Data
The CASE REST APIs are designed to provide easy access to CASE data published by an issuing agency. However, note that the CASE spec is designed and intended to support the publishing of learning standards and other competency data that, once published, rarely changes. Therefore, consumers of an agency’s CASE data should by best practice implement a caching system that may check periodically for updates to the agency's competency frameworks, but does not constantly hit the CASE APIs. If an agency encounters too much traffic on their CASE APIs, they may decide to meter traffic on the APIs in some way.
Markdown and LaTeX
CASE best practice is to strongly discourage html tags in fullStatement, notes, or descriptions fields. The reason for this restriction is that consumers of CASE competencies may have needs to render competency data in “plain text” format (e.g. on a K-12 student report card); in such a situation where the html is not rendered, html tags would make the competency data difficult if not impossible to read. (HTML tags may also be considered a security risk.)
Markdown
However, CASE 1.1 specifies that, whenever possible, Markdown SHOULD be supported by clients when rendering the CFItem fullStatement, and notes/descriptions on all CASE objects, e.g. by using a Javascript library such as Marked. Markdown is supported because one of the primary goals of the Markdown syntax is that “unrendered” Markdown will still be readable.
There are many “flavors” of Markdown, and CASE 1.1 does not specify exactly which flavors are supported, nor does it specify exactly which parts of the Markdown syntax should be rendered. But a basic list of formatting options that we recommend be supported includes:
Inline Elements:
*italics*or _italics_ for an italicized string (html <em> tag)**bold**or __bold__ for a bold string (html <strong> tag)code(html <code> tag)[link](https://example.com)for a linkfor an image:Lists:
May be supported: A bulleted list is created by starting a line with a single *, -, or + character. Multi-level lists can be created by indenting the starting *, -, or + of a line with a tab character or two space characters. So this:
Should render like this:
May be supported: An ordered list is created by starting each line with a number followed by a period. So this:
Should render like this:
Note that in order to support lists, CASE fields may include newline characters (\n). When unrendered, a newline character is expected to be treated the same as a space character, but when rendered via a library such as Marked, the newlines will be translated according to the Markdown syntax rules.
LaTeX
Competencies for some academic disciplines, particularly STEM fields, often include mathematical and/or scientific notations, and there are situations where understanding of a competency requires the expression of a complex formula or construct that cannot be adequately rendered in plain text. For these situations, CASE 1.1 specifies that, whenever possible, clients SHOULD support the rendering of LaTeX-style math statements, e.g. by using a Javascript library such as KaTeX or MathJax.
LaTeX is an extremely rich document preparation syntax; CASE expects only that LaTeX “math mode” be supported. More specifically, strings surrounded by dollar signs (
\$) should be rendered as equations; and to allow for the use of dollar signs in non-math contexts, we recommend that equations should only be rendered if:\$of an equation has [a space character, an opening parenthesis, or an opening square or curly bracket] immediately before it, but is immediately followed by a non-space character,\$of an equation is immediately preceded by a non-space character, but is immediately followed by [a space character, a closing parenthesis, a closing square or curly bracket, or a comma, period, colon, semicolon, or question mark].Thus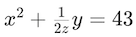 ), whereas
), whereas
$x^2 + \frac{1}{2z}y = 43$should be rendered as an equation (\$5.10should be rendered as $5.10.Note that that like Markdown, an unrendered LaTeX equation should still be intelligible to a reader, especially if they have some familiarity with the subject matter. Coding an equation as LaTeX serves to explicitly signal that the string should be interpreted as an equation, so it may be worth coding even single variables (e.g.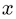 ) and simple formulas (
) and simple formulas (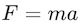 ). See this page for a useful summary of some of what one can do with LaTeX math formatting.
). See this page for a useful summary of some of what one can do with LaTeX math formatting.
\$x\$, rendered as\$F = ma\$, rendered asSee this appendix for more examples of markdown text and LaTeX and how they would be properly rendered.
CASE in the 1EdTech Ecosystem
CASE is used by many other 1EdTech standards to align content and learning activity to academic standards. These sections should provide you an introduction to how each specification utilizes CASE. For more details on implementing these related specifications please refer to the linked implementation guide in each section.
A primary use of CASE with many 1EdTech specifications is aligning content resources to specific CASE GUIDs. This allows any system utilizing those specifications to have the necessary information to then either process using their own internal implementation of CASE or to fetch the appropriate framework with the CASE Item URI or GUID as described in this document. Each specification section below will explain how to make that CASE alignment for that context, or link to relevant sections in that specification's own implementation guide.
Common Cartridge (CC)
Common Cartridge as a content packaging standard used to move and link content between educational systems. Each cartridge is a combination of learning resources, an organization and ordering of those resources, and metadata. In that metadata Common Cartridge supports aligning both the entire cartridge to CASE GUIDs, and each individual resource. The Common Cartridge 1.4 Implementation Guide describes how to make these alignments.
One of the primary use cases for Common Cartridge and CASE is packaging many LTI links together that represent a lesson or a whole course. This allows an importing system to have CASE-aligned LTI links and gradebook items. How this all works together is described in the LTI section below.
Learning Tools Interoperability (LTI)
LTI is used to integrate learning tools into a learning platform like an LMS. Common examples are embedding content like textbook readings and quizzes or other graded activities. LTI does not yet have explicit support for communicating aligned CASE GUIDs to content, but if the LMS supports aligning gradebook columns or content links to CASE then any LTI assessments or reading activity can still be aligned to the appropriate academic standards in that context.
LTI Resource Search (LTI-RS)
Learning Tools Interoperability® (LTI®) Resource Search is a standard that defines how to search digital repositories for a set of resources. This search is often performed on content that is already in a Learning Object Repository (LOR) or in the Common Cartridge (CC) format. The LTI Resource Search implementation guide has a brief section on Searching for Resources by Learning Objective.
Open Video (OV)
The OpenVideo Standard is an XML interface for the ingestion of captured content. A video could be included inside of a Common Cartridge or discovered via LTI Resource Search. In those cases, it is possible to align a CASE item to a video.
Comprehensive Learner Record (CLR)
The CLR standard interplays with CASE through associations for achievements. Each achievement can have an association or many associations to CASE CFItems, rubrics or other URIs. The intent, functionally, is to use CASE items to define ‘Achievements’, ‘Skills’ and ‘Competencies’ and then to award them as CLR achievements (Either CLR Achievement or Open Badge format).
Open Badges (OB)
Open Badges are information-rich visual records of verifiable achievements earned by recipients and easily shared on the web and via social media. The Open Badges standard describes a method for packaging information about accomplishments, embedding it into portable image files as digital badges, and includes resources for web-based validation and verification. Open Badges describe who earned it, who issued it, the criteria required, and in many cases even the evidence and demonstrations of the relevant skills. Open Badges BadgeClass records can reference CF Item CASE URIs through alignment.
In order for alignment to a CF Item to be resilient over time as the CASE provider may adopt future versions of the specification, there must be a canonical URI for the item, and that URI must be identified in the alignment instead of using a REST path that will change for that item over time, such as one that includes the CASE version identifier. In order to ensure that CASE CF Items published by a system are ready to be referenced in badges and other resources on the web, identify the canonical URI of each CF Item with the “uri” property that will not change for the lifespan of that item, and make the CASE data for that item available at that URI, outside of the identified GET CF Item REST path. A great pattern for doing this would be to implement the CASE JSON-LD Binding to publish the CF Item data in JSON-LD at the canonical URIs, and publish CASE JSON using the REST paths.
CASE with Open Badges 3.0 (OB 3.0) and Comprehensive Learner Record 2.0 (CLR 2.0)
Competencies or related learning outcomes can be referenced within digital credentials in the asserted Achievement using alignment fields. More information is available:
The credential data models for Achievements are shared by the Open Badges Specification v3.0 and Comprehensive Learner Record Standard v2.0.
OneRoster or EDU-API
OneRoster (K-12) or EDU-API (Higher Ed) allow for the standardized exchange of data between the transactional systems that manage education administration and teaching and learning. EDU-API is under development as of the time of authoring this document, so information that follows will reflect OneRoster only. EDU-API intends to follow OneRoster’s model and incorporate many, if not most, of the same capabilities.
OneRoster interplays with CASE by linking curriculum (academic standards), definiting courses (via a Framework), and then ties to people. In addition, OneRoster version 1.2 includes an Assessment Profile that accommodates standards, and can support alignments at the question or response level
Caliper
Caliper Analytics enables institutions to collect learning data from digital resources to better understand and visualize learning activity and product usage data, and present this information to students, instructors, and advisors in meaningful ways to help inform student recruitment and retention plans; program, curriculum, and course design; and student intervention measures.
Caliper can interplay with CASE alignments to events. The Caliper 1.2 implementation guide describes how to align CASE GUIDs to an event
Question and Test Interoperability (QTI)
Question and Test Interoperability (QTI) identifies and defines the formats, protocols, and points of interoperability that save users and suppliers time and money in the development, delivery, and outcomes of assessments. QTI test items can have standards alignments. In addition, some framework types - like SmarterBalance - can be blueprints for content assessment framework
Best Practice Implementation Details for CASE Attributes
This section contains recommendations and findings for individual fields within the specification.
Field Length
While CASE itself sets no arbitrary limits, the following fields are considered best practice for field length limits within CFItem. When these limits are exceeded, implementers should add an error message that the framework loaded but with possible errors such as values being truncated in storage, or not being fully visible in the user interface.
Maximum lengths for all fields is as follows from this source document:
CFDocument
version- recommend using a year or date in this field to communicate implementation or adoption
lastChangeDateTime - in all instances of other data structures
ISO 8601
Specify in UTC
statusStartDate
ISO 8601 (date only)
Specify in UTC
statusEndDate
ISO 8601 (date only)
Specify in UTC
language
While we reference RFC 5646 for this property, the specific implementation of this format should be in the browser locale supported format : en_US and not en-US
This is recommended in order to simplify international adoption for application developers
adoptionStatus
While there is no enumeration for this field in the specification, certain values are already in use within existing implementations. The meaning of these values are meant, in part, to convey CRUD functionality considerations in application development and implementations. Example adoptionStatus values and CRUD considerations may include:
Draft- Unlimited Options
Adopted - Change only Associations and CF Definitions
Deprecated - No changes to the CF or the CF Definitions can be allowed
When a CFDoc is Deprecated, an effort to make associations between it and the new CFDoc should be made using the ‘replacedBy’ association type in order to allow for long term transcripting as well as legacy content re-correlation
CFItem
CFItem Ordering in a CFDoc
CASE Items are displayed in various contexts and Items may be also be used more than once. Use this guidance to decide how to display items in an interface for users:
No other ordering mechanism is part of the standard; when the sequencenumber is not present for any or all ItemAssociations, implementations may choose to have fallback business rules to order items (which may include other attributes such as humanCodingScheme, fullStatment, or even listEnumeration) but the display order is not guaranteed to be the same between implementations.
Note that the sequence is for display purposes only, there is no pedagogical implication based on the sequencenumber. Other associationTypes (such as precedes and hasSkillLevel) can be used for pedagogical reasons.
humanCodingScheme
While this property is optional, it is highly recommended that a standardized, human readable notation format be established for each CFDoc and applied to each CFItem. This provides:
Unique node identification not only within the CF, but also across multiple CFs
A simplified hierarchy that can be understood by end users to understand where the standard exists in the CF. For example:
NT.CCSS.MTH.10.1.G.1
NT = National
CCSS = Common Core
MTH = Math
10 = Adopted 2010
1 = Grade
G = Geometry
1 = Learning Standard 1
This also provides a simplified notation that can be easily recognized when ingested and presented by third party LMSs and assessment engines
Node Normalization
Some taxonomies may not have a suitable Human Coding Scheme value that applies at all levels within the hierarchical structure. Often these nodes are never meant to be the target of an association. In these situations it is valid to have a node with an assigned Human Coding Scheme solely for the purpose of normalizing the taxonomy.
Example:
MTH.15.9-12
MTH.15.9-12.F
MTH.15.9-12.F.BF
MTH.15.9-12.F.BF.A
MTH.15.9-12.F.IF
MTH.15.9-12.F.IF.A
The MTH.15.9-12.F CFItem had to be added in order to create a parent structure the MTH.15.9-12.F.BF and MTH.15.9-12.F.IF nodes could be a isChildOf in CFAssociations.
CfItemTypeof a hierarchy if not present in humanCodingScheme.
fullStatement
abbreviatedStatement
language
conceptKeywords
listEnumeration
CfItemType
CFItemType is not a controlled vocabulary and thus there will be differences in ItemTypes referenced.
See the CFItemType section for specifics.
Notes
Notes should be used for implementation of the competency or non-essential information. It is intended to be shown to the consumer when possible to assist with understanding of the CfItem’s fullStatement. Georgia and other states have used the Notes field to expand upon the intent of the fullStatement.
Notes should not be used for actionable insights, actionable insights should be reserved for association types and other stratified items.
Clients SHOULD support basic Markdown and Latex math formulas in notes fields.
Other notes:
In the above example, the Notes should have been expanded out as additional children nodes instead of all in notes so that content/assessment could be tagged individually to those bullets.
While there is no predefined character limit within the CASE standard, implementations may set limits.
alternativeLabel
Currently there is no clear use case for alternativeLabel; thus it is recommended this field not be used and will be deprecated in a future version of CASE.
CFAssociations
originNodeURI and destinationNodeURI
originNode/destinationNode Identifier:
This will normally be either a CFItem or CFDoc identifier. At this time there is no common understanding/use of associations between CFDocuments.
Use UUID where possible.
In cases where external (AB, ASN, EdGate) identifier associations are needed, those identifiers would be in this field.
URI:
When representing identifiers from third parties that do not have resolvable CFItem URIs then creating non-URL formatted URIs such as
urn:<namespace>:<identifier>are acceptableExample:
urn: uuid:7dde88be-5032-11e6-9639-12c6ab5e124d
SequenceNumber:
This is the only method in the CASE standard that defines a display sequence for items that all have the same parent. This is used because through the use of association groups, a CFItem could have a different parent depending on the grouping.
See CFItem for a full description of ordering considerations.
As described in an earlier section, there is no requirement that the origin or destination of an association must be part of the ame framework as the association.
CFAssociationTypes
Example Usages
isChildOf
CFItem to Parent CFitem
CFItem to Parent CFDoc (only for top nodes)
exactMatchOf
CFItem to CFItem in different CFDocs
replacedBy
CFItem in Deprecated CFDoc to CFItem in Draft or Adopted CFDoc
Definitions and examples are provided in the Association Types section.
CFDefinitions
CFSubjects
hierarchyCode
This field is intended to allow a meaningful local code that can be leveraged to enforce both a hierarchy as well as a clear notation users can identify
Generally, an organization’s CFSubjects can be as simple or as complex as the org requires
Example 1
ELA - Language Arts
Math - Mathematics
Example 2
ELA - Language Arts
ELA.1 - Grade 1 Language Arts
ELA.1.V - Grade 1 Vocabulary
Math - Mathematics
Math.1 - Grade 1 Language Arts
Math.1.G - Grade 1 Geometry
CFItemTypes
typeCode
This field is intended to allow a meaningful local code that can be leveraged to enforce both a hierarchy as well as a clear notation users can identify. The publisher of the framework is responsible for determining the structure of the hierarchy and CF Item type vocabulary for the purposes the framework was created for.
When defining CF Item Types, due to changing demands within a education org, it is recommended to use a date or year identifier within CF Item Types so that should changes be necessary after a CFDoc has been deprecated, target org CF Item Types can be replaced with a new version while allowing historical fidelity for long term transcript needs. There is a lastchangeDate that would allow for this to be incorporated into CFPackages
Generally, a organizations CFItemTypes can be as simple or as complex as the org requires
Example 1:
GA.10.1 - Target
GA.10.2 - Standard
Example 2:
GA.10 - Georgia Item Types 2010
GA.10.1 - Document
GA.10.1.1 - Strand
GA.10.1.1.1 - Topic
GA.10.1.1.1.1 - Standard
GA.10.1.1.1.1.1 - Sub Standard
Title: To be used to give a title to the Item Type (eg KSAO)
Description: Knowledge, Skills, Abilities and other characteristics
Hierarchy code: in the above example as well as in real life, often frameworks are structured so that different levels of the framework denote different types of information. Thus top level nodes could be “Subjects, Major Branches, Strands, Substrands, Levels, KSAO’s”. If the organization wants to enforce a hierarchy for these types of codes then they should have their item types have it.
Dealing with Same-Named Packages
When one server (eg CASE Network) ingests multiple packages from multiple servers, it is inevitable that there will be duplicate titles. This should be acceptable as long as when users are selecting a CfItemType they are selecting the title that comes from the server they want (eg has the same description etc). Perhaps when selecting the Type in the CFItem Editor controls are enacted that only shows CfItemTypes that belong to that users organization on the server.
CFConcepts
hierarchyCode
This field is intended to allow a meaningful local code that can be leveraged to enforce both a hierarchy as well as a clear notation users can identify
When defining concepts, due to changing demands within an education org, it is recommended to use a date or year identifier within concepts so that should changes be necessary after a CFDoc has been deprecated, target org concepts can be replaced with a new version while allowing historical fidelity for long term transcript needs
Generally, an organization's CFConcepts can be as simple or as complex as the org requires
Example 1:
GA.10.Mac - Georgia Math Concepts 2010
GA.10.ELAc - Georgia English Language Arts Concepts 2010
Example 2:
GA.10.Mac - Georgia Math Concepts 2010
GA.10.Mac.1 - Grade 1 Math Concepts
GA.10.Mac.1.NBT - Grade 1 Number and Operations in Base Ten
GA.10.Mac.ALG - Algebra Math Concepts
GA.10.Mac.ALG.APR - Algebra Arithmetic with Polynomials and Rational Expressions
GA.10.ELAc - Georgia English Language Arts Concepts 2010
CFLicense
licenseText
This field is intended to include all the legal licensing text an org may require to protect business needs
licenseDescription: Description of why the license was implemented
Future CASE iterations should have a link to the license being implemented eg to Creative Commons machine readable page
Extensions
While the CASE 1.0 spec explicitly disallowed “proprietary data elements” in CASE JSON, CASE 1.1 explicitly allows CFItems, CFDocuments, and CFAssociations, and other entities to be “extended” to include field names and values that are outside the spec.
For example, a CASE 1.1 CFItem could be specified as:
extensionsfield, and/or any extension sub-fields, that the system doesn’t “know” or “care” about.extensionsfield, we avoid namespace collisions with field names that may be introduced in future CASE versions.API
JSON Payloads
Ordering
Property ordering within a given object should not be necessary
If you want to understand ordering of CFItem objects within a CFPackage, this is explained in the section CF Item Ordering in a CF Doc
Output and ingest systems should key off the property names and not the order of those properties within a payload
{identifier, uri, title} should work as well as {title, identifier, uri}
URI datastructure
In the CFDoc, CFItem, and CFAssociation data include a consistent representation for CF Definition URI entries. This is to ensure the greatest flexibility for consumers when parsing payloads
Example:
"CFDocumentURI": { "title": "Common Core State Standards for Math ", "identifier": "c6496676-d7cb-11e8-824f-0242ac160002", "uri": "https://casenetwork.imsglobal.org/uri/pc6496676-d7cb-11e8-824f-0242ac160002" },Using OAuth 2 to Authorise Access to the Service Provider
If authorised access to one of more endpoints is required, the patterns defined in the 1EdTech Security Framework 1.1 [Security, 21] SHOULD be used. It is RECOMMENDED that the OAuth 2.0 Client Credentials Grant approach is used (see Section 4.1 in [[SECURITY-11]]). This approach is already used by several 1EdTech service-based standards e.g. OneRoster 1.2 OneRoster 1.2 Rostering Service REST Binding 1.0.
Derived CFDocuments and Third Party Use
Scope and Sequence Frameworks
A scope and sequence framework contains information about a course overarching goals, timeline, integral tasks and assessment.
K-12 Versioning Model
Versioning overview.
An approach to versioning can be managed by new CFDOC definitions. Given the following three defined Adoption Status values, for each status only specific functions should be allowed per the specification.
*Core CRUD Functionality and Definition CRUD Functionality are represented across the columns above. No: Once published, defining attributes are still editable in order to allow for refinement without directly changing the LS Doc.
*With exception for a Last_Change_datetime
K-12 Versioning Workflow Example
*At this point, the defining attributes of the deprecated CF Doc need to be locked. They can be used, by other new documents, but they cannot be changed. This is to allow historical reference. If an organization is redefining their defining attributes, they need to establish new hierarchies to support those changes in order to ensure historical reference. This speaks to the importance of establishing a best practice for defining hierarchy values.
Allowing Mark-up: Markdown and LaTeX
CASE best practice is to strongly discourage HTML tags in fullStatement, notes, or descriptions fields. The reason for this restriction is that consumers of CASE competencies may have needs to render competency data in “plain text” format (e.g. on a K-12 student report card); in such a situation where the HTML is not rendered, HTML tags would make the competency data difficult if not impossible to read. (HTML tags may also be considered a security risk.)
Markdown
However, CASE 1.1 specifies that, whenever possible, Markdown SHOULD be supported by clients when rendering the CFItem fullStatement, and notes/descriptions on all CASE objects, e.g. by using a Javascript library such as Marked. Markdown is supported because one of the primary goals of the Markdown syntax is that “unrendered” Markdown will still be readable.
There are many “flavors” of Markdown, and CASE 1.1 does not specify exactly which flavors are supported, nor does it specify exactly which parts of the Markdown syntax should be rendered. But a basic list of formatting options that we recommend be supported includes:
Inline Elements:
*italics*or _italics_ for an italicized string (html<em>tag)**bold**or __bold__ for a bold string (html<strong>tag)code(html<code>tag)[link](https://example.com)for a linkfor an image:Lists:
May be supported: A bulleted list is created by starting a line with a single *, -, or + character. Multi-level lists can be created by indenting the starting *, -, or + of a line with a tab character or two space characters. So this:
Should render like this:
May be supported: An ordered list is created by starting each line with a number followed by a period. So this:
Should render like this:
Note that in order to support lists, CASE fields may include newline characters (\n). When unrendered, a newline character is expected to be treated the same as a space character, but when rendered via a library such as Marked, the newlines will be translated according to the Markdown syntax rules.
LaTeX
Competencies for some academic disciplines, particularly STEM fields, often include mathematical and/or scientific notations, and there are situations where understanding of a competency requires the expression of a complex formula or construct that cannot be adequately rendered in plain text. For these situations, CASE 1.1 specifies that, whenever possible, clients SHOULD support the rendering of LaTeX-style math statements, e.g. by using a Javascript library such as KaTeX or MathJax.
LaTeX is an extremely rich document preparation syntax; CASE expects only that LaTeX “math mode” be supported. More specifically, strings surrounded by dollar signs (
\$) should be rendered as equations; and to allow for the use of dollar signs in non-math contexts, we recommend that equations should only be rendered if:\$of an equation has [a space character, an opening parenthesis, or an opening square or curly bracket] immediately before it, but is immediately followed by a non-space character,\$of an equation is immediately preceded by a non-space character, but is immediately followed by [a space character, a closing parenthesis, a closing square or curly bracket, or a comma, period, colon, semicolon, or question mark].Thus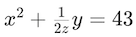 ), whereas
), whereas
$x^2 + \frac{1}{2z}y = 43$should be rendered as an equation (\$5.10should be rendered as $5.10.Note that that like Markdown, an unrendered LaTeX equation should still be intelligible to a reader, especially if they have some familiarity with the subject matter. Coding an equation as LaTeX serves to explicitly signal that the string should be interpreted as an equation, so it may be worth coding even single variables (e.g.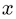 ) and simple formulas (
) and simple formulas (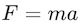 ). See this page for a useful summary of some of what one can do with LaTeX math formatting.
). See this page for a useful summary of some of what one can do with LaTeX math formatting.
\$x\$, rendered as\$F = ma\$, rendered asThe appendix Examples of rendered markdown shows examples of markdown text and how they would be properly rendered.
Evolving Framework
- A course syllabus or course framework which may add skills or remove skills during the delivery of the course or between quarters for a given year (periodic updates). Those skills are often sourced from a master topical framework.
- A minor update or errata to an adopted framework where one or a small number of items are replaced with new items to correct errors or add clarity.
- A refinement or decomposition into sub-skills or assessment or other use.
Across these cases there are the types of change to consider:
- Addition (New item, type, skill or section)
- Replacement (Changing an item by replacing it with a new item and using replaced by)
- Deletion (Or deprecating an item)
- Re-organizing (Changing the hierarchy or sequence)
If a revision is published, it should include a version number in the CF Doc notes as well as a narrative description of the changes across the framework.
Any new item can be identified by the item's last change date.
Related items should have a replacedBy Association. However, they should not be deleted. Ideally an item “Deprecated” state might be supported in 1.1?
2. Consumer will request a payload from the Provider where the Consumer provides the CF Document sourcedId.
3. Compliant JSON payload will be generated by Provider based on a lookup of the CF Packages. All necessary data points associated with the CF Packages will be included in the payload.
a. CF Document (of sourcedId provided)
b. CF Items
c. CF Associations
d. CF Definition
e. CF Concept
f. CF License
g. CF Association Groupings
h. CF Subjects
i. CF Rubrics
j. CF Rubric Criterion
k. CF Rubric Level
4. Provider sends the payload to the Consumer.
5. Consumer receives the JSON payload.
6. Consumer processes the payload successfully.
Examples of rendered Markdown and LaTeX
Basic Formatting
* Introduce and define topic and/or entity for audience
* Describe attributes and characteristics with facts, definitions, and relevant details
Inline Math Formulas
More Complex Math Formula
Complex Table and Formatting

Select True or False for each statement based on the scatter plot.
| **Statement** | **True** | **False** |
|---|---|---|
| There is a positive association between average weight and average heart rate for animals. | | |
| Animals with higher body weights tend to have lower heart rates than animals with lower body weights. | | |
| For animals weighing 20 lbs or less, there is a linear association between average weight and average heart rate. | | |
**Rubric:** (1 point) Student determines each statement as being either true or false (e.g., F, T, T) Each statement that interprets the scatter plot and may involve clustering in reference to the line of best fit, positive or negative associations, linear associations, nonlinear associations, or the effect of outliers.
Connections to Other Relevant Standards
Ed-Fi
Ed-Fi Unifying Data Model:
For UML representations, the Learning Standards and Learning Objectives entities are surfaced in the Ed-Fi UDM in the context of:
Teaching and Learning Domain : https://techdocs.ed-fi.org/display/ETKB/Ed-Fi+Technology+Version+Index
Assessment Domain: https://techdocs.ed-fi.org/display/ETKB/Ed-Fi+Technology+Version+Index
Student Academic Record Domain: https://techdocs.ed-fi.org/display/ETKB/Ed-Fi+Technology+Version+Index
Here is a tech article that provides additional information related to how learning standards and learning objectives work w.r.t to assessment: http://techdocs.ed-fi.org/display/DASH20/Assessment+Model+Patterns+in+the+Ed-Fi+Data+Standard+v2.0
Ed-Fi Bulk/XML - Links to concrete instantiation in XSD
Domain Entities:
Learning Standard : https://schema.ed-fi.org/schemadocs/schema/learningstandard.html
Learning Objective: https://schema.ed-fi.org/schemadocs/schema/learningobjective.html
Ed-Fi XML Interchanges:
Ed-Fi Standards Interchange : https://techdocs.ed-fi.org/display/ETKB/Ed-Fi+Technology+Version+Index
Assessment Interchange: https://techdocs.ed-fi.org/display/ETKB/Ed-Fi+Technology+Version+Index
Ed-Fi API/JSON - Here is are swagger links to how they surface in the Ed-Fi API
CEDS